

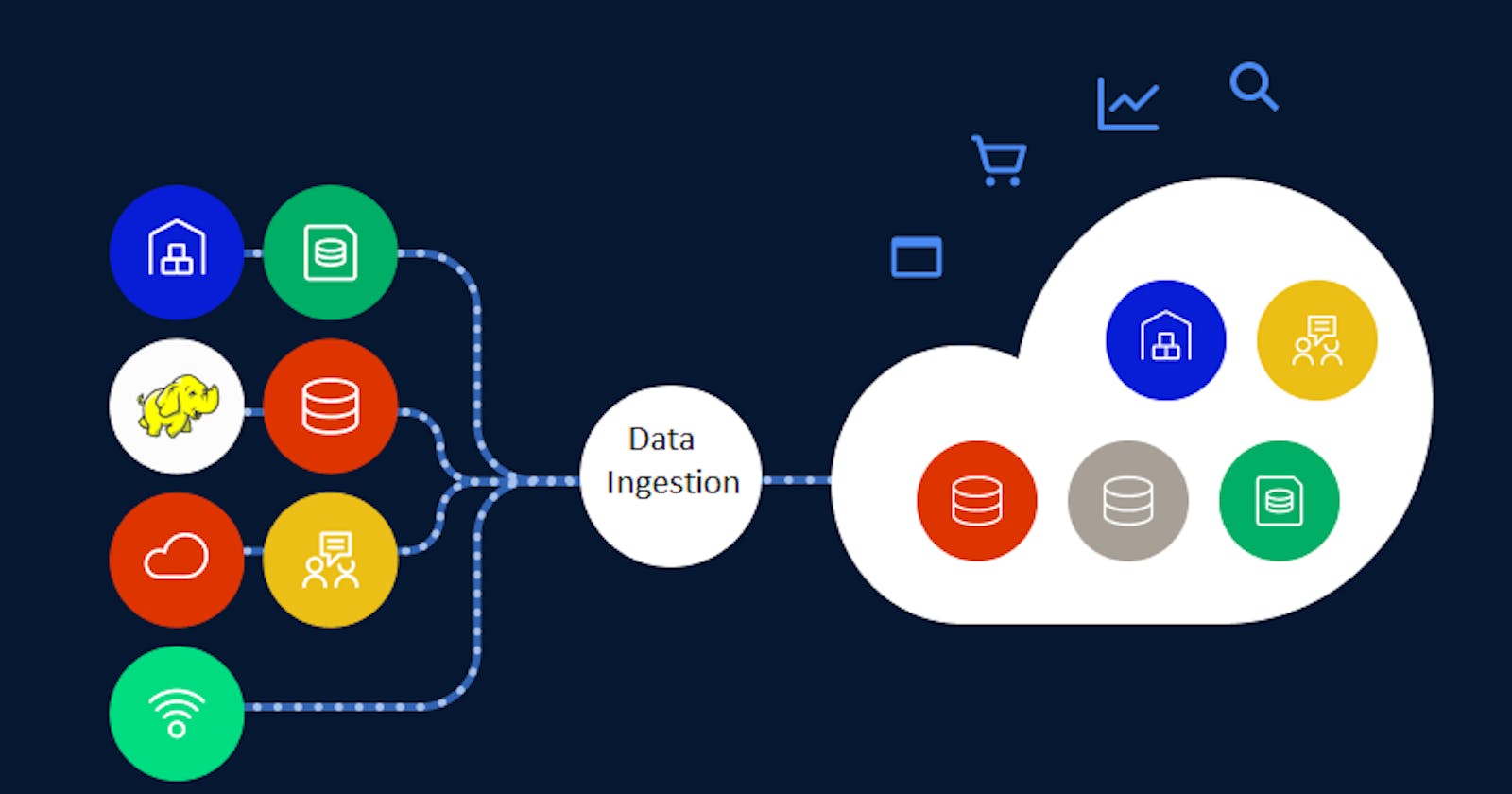


Data Ingestion is a process of importing, transferring, loading and processing data for later use or storage in database. It Involves connecting to various data sources, extracting the data, and detecting changed data. The data might be in different formats and come from various sources, including RDBMS, other types of databases, S3 buckets, CSVs, or from streams. Since the data comes from different places, it needs to be cleansed and transformed in a way that allows you to analyze it together with data from other sources. Otherwise, your data is like a bunch of puzzle pieces that don’t fit together.
You can ingest data in real time, in batches, or in a combination of the two (this is called lambda architecture). When you ingest data in batches, data is imported at regularly scheduled intervals. This can be very useful when you have processes that run on a schedule, such as reports that run daily at a specific time. Real-time ingestion is useful when the information gleaned is very time-sensitive, such as data from a power grid that must be monitored moment-to-moment. Of course, you can also ingest data using a lambda architecture. This approach attempts to balance the benefits of batch and real-time modes by using batch processing to provide comprehensive views of batch data, while also using real-time processing to provide views of time-sensitive data.
Real-Time Data Ingestion: Data ingestion in real-time, also known as streaming data, is helpful when the data collected is extremely time-sensitive. Data is extracted, processed, and stored as soon as it is generated for real-time decision-making. For example, data acquired from a power grid has to be supervised continuously to ensure power availability.
Batch Data Ingestion: When ingestion occurs in batches, the data is moved at recurrently scheduled intervals. This approach is beneficial for repeatable processes. For instance, reports that have to be generated every day.
Lambda Architecture: The lambda architecture balances the advantages of the above-mentioned two methods by utilizing batch processing to offer broad views of batch data. Plus, it uses real-time processing to provide views of time-sensitive information.
Why Is Data Ingestion So Important?
Data ingestion helps teams go fast. The scope of any given data pipeline is deliberately narrow, giving data teams flexibility and agility at scale. Once parameters are set, data analysts and data scientists can easily build a single data pipeline to move data to their system of choice. Common examples of data ingestion include:
Move data from Salesforce.com to a data warehouse then analyze with Tableau
Capture data from a Twitter feed for real-time sentiment analysis
Acquire data for training machine learning models and experimentation
Data Ingestion Parameters
There are typically 4 primary considerations when setting up new data pipelines:
- Format — what format is your data in: structured, semi-structured, unstructured? Your solution design should account for all of your formats.
- Frequency — do you need to process in real-time or can you batch the loads? Velocity — at what speed does the data flow into your system and what is your timeframe to process it?
- Size — what is the volume of data that needs to be loaded? It’s also very important to consider the future of the ingestion pipeline. For example, growing data volumes or increasing demands of the end users, who typically want data faster.